Using S3 and Scale out Repos to replace Tape
Whilst tape may not be quite dead yet, I'm keen to do everything I can to push it toward an early grave.
One of the main reasons for using Tape is to maintain long term GFS (Grandfather/Father/Son) backup chains with weekly/monthly and yearly full backups retained for compliance and long term archive.
The downside of this is that is you ever need to restore from those older point in time backups, then the RTO is terrible. You are likely to need a tape retrieval from vault, load into libraries and then a serial restore from a slow medium.
Now, what if I told you that we could keep ALL your archive backup online and available? Well, with vBridge S3 service on Cloudian and Veeam we can.
First set up a Scale-Out Backup Repository. In this case I have a capacity tier on vBridge s3 storage, with 7 day object lock (to protect against ransomware attacks or malicious internal admins), and all backups written to Object as soon as they are created.
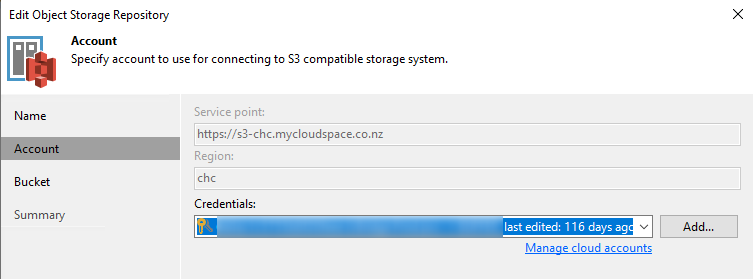
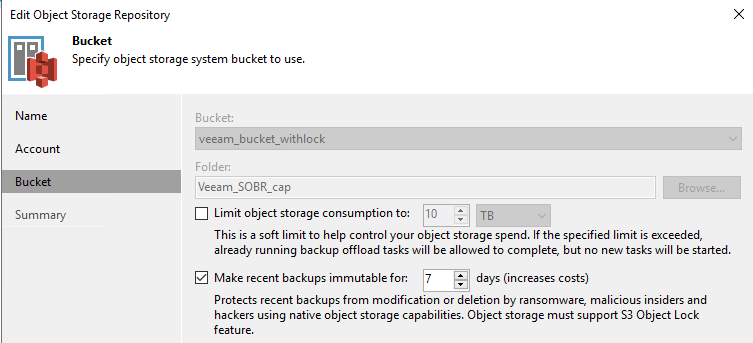
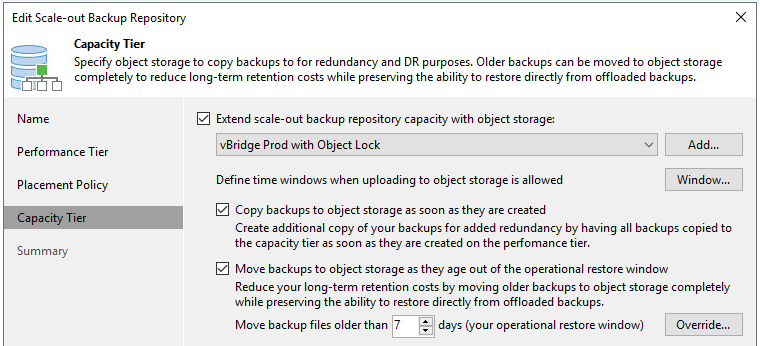
Next, create a Backup Copy job. We use Backup Copy to replicate the duplication of data as per tape and also to introduce the GFS rules. For this copy job below we want to keep 10 basic restore points, 5 weekly copies, 12 monthly backups and 5 yearly backups. Of course you can set these to whatever retention policies you need.
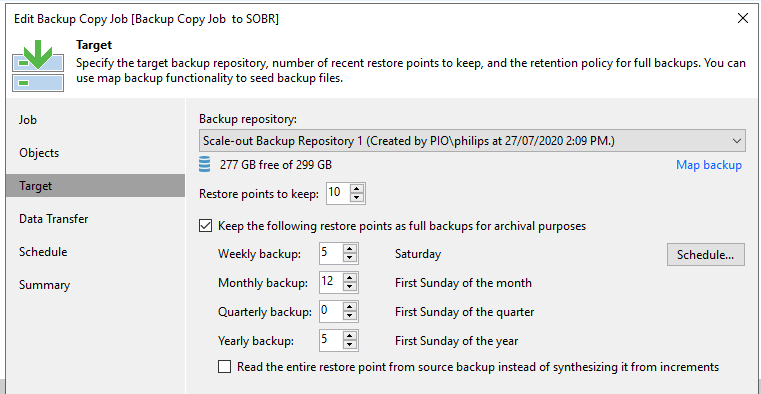
A Backup copy takes it's data from a normal copy job repository. This means that the data is not copied from source every time, thus reducing the load on the production environment.
Leave this running for a couple of months and we can see the GFS at work.
If we look to restore a VM protected by the copy job and look at the available restore points:
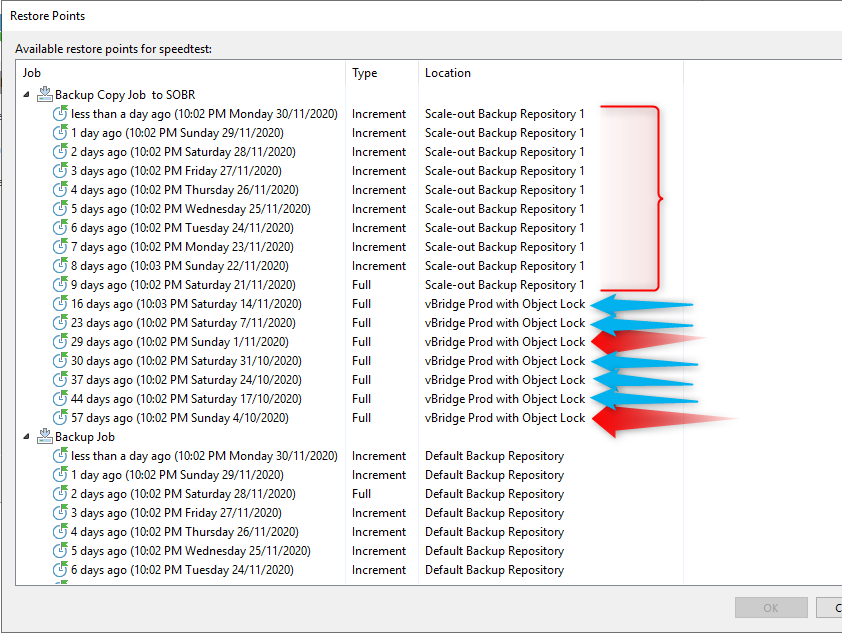
We have out 10 Basic restore points, the 5 GFS weekly (Saturday) jobs, and a couple of monthlies (Sunday). I now have all the RPO in order to meet my policy.
At this point, I can do a restore of any point in time, without needing to recall tapes. If I'm just after a small amount of data I can even do an Instant Restore of the VM with the VM published from the SOBR and S3 Object store. This gives me an RTO of minutes rather than the hours or days associated with tape recovery.
The smart thing with Veeam is that it will only restore changed blocks from Object if it needs to, most of the restored VM blocks are likely to be on the local performance tier of the SOBR. This helps with speed and keeping restore costs down.
Be aware that S3 recoveries from AWS can add up with data egress charges and per-operation charges (especially with Glacier). Better still use the NZ located vBridge s3 service where there are no operational or data changes, you only pay a flat fee for capacity used.
The downside? Well we don't have air gapped, offline media. But with Object Lock we are getting close.....