Is it the network?
"It's a network problem" It's a phrase that flies around IT and business with reckless abandon. It's an easy target, the networks just toil away in the background moving packets.
Networks certainly used to be a bottleneck, but with newer technologies, including Gigabit fibre to the home, is that always the case?
These days you expect desktops/laptops to connect at gigabit speeds, these deliver more bandwidth than you can deliver off a SATA hard drive. Please don't run a speedtest from your old laptop with slow hard drive and average network card and cpu and complain that you are not getting 'full network speed'.
In the datacenter we only really use 10Gb ethernet or more. At vBridge we have internal links at 200Gb ethernet and core speeds well over 100Gb. Quite simply we have more bandwidth in the datacenter than we can realistically use, our core utilisation is very low and we are a long way from hitting any sort of congestion within the datacenter.
All that being said, there are still issues where the fingers get pointed at the network. One case is with TCP Re-transmits.
TCP/IP is a very reliable protocol that holds the internet together. One way that it "just works" is that if a packet isn't acknowledged in a timely manner it will get resent. This is how TCP/IP is supposed to work and isn't necessarily a bad thing. But as with all things - it depends. If you go back to the mantra of 'monitoring everything', then monitoring may highlight TCP Retransmits or Connection failed (see Perfmon) and you may ask yourself why. In many cases it can be the network, especially if the target is somewhere over the internet, or it could be due to packets being dropped on the network due to congestion or full buffers, or misconfigurations.
But if it's not any of those then what?
Below is an interesting observation and a case of troubleshooting the lost packets.....
So if you see something in your monitoring that shows a low, but constant level of re-transmits it must be a network problem right?
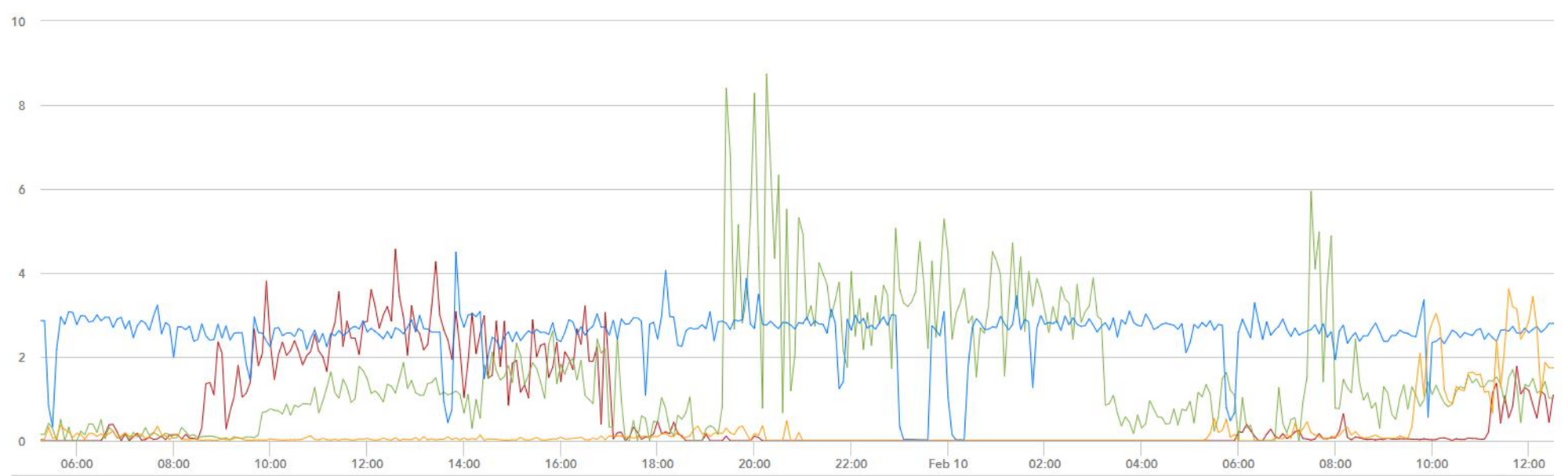
But after doing all the basic troubleshooting, there are no packets being dropped on any network links and nothing anywhere close to saturating a link. The servers are pretty busy, so we start looking at the OS.
The next step up from the network is the OS drivers. Most of the time these work fine with the vendor supplied defaults. But when you have compute blades with multiple 25Gb NICs, and a non blocking network, can your OS deal with the packets we are sending it?
If the OS itself is maxing out on resources (cpu, memory etc.) then it's not going to be able to respond to network packets or pings in a timely manner. However, if that's all good then take the next step...
We recommend using the VMXNET3 paravirtualised drivers for anything on top of VMware. These drivers have a couple of ring buffers to receive data from the NIC, packets stay here until the OS processes them.
If the data comes off the network faster than the OS can deal with them, then the buffers may fill up. And full buffer means that the driver has no option but to drop the packet.
It takes a fairly deep dive using vsish on ESX to pull the guest OS VMXNET3 stats from the host. But when we do....
vsish -e get /net/portsets/DvsPortset-0/ports/67108925/vmxnet3/rxSummary
stats of a vmxnet3 vNIC rx queue {
LRO pkts rx ok:331366
LRO bytes rx ok:3430896796
pkts rx ok:39717579
bytes rx ok:52281582095
unicast pkts rx ok:39618816
unicast bytes rx ok:52267695695
multicast pkts rx ok:57205
multicast bytes rx ok:10518880
broadcast pkts rx ok:41558
broadcast bytes rx ok:3367520
running out of buffers:891
pkts receive error:0
1st ring size:512
2nd ring size:512
# of times the 1st ring is full:891
# of times the 2nd ring is full:0
fail to map a rx buffer:0
request to page in a buffer:0
# of times rx queue is stopped:0
failed when copying into the guest buffer:0
# of pkts dropped due to large hdrs:0
# of pkts dropped due to max number of SG limits:0
pkts rx via data ring ok:0
bytes rx via data ring ok:0
Whether rx burst queuing is enabled:0
current backend burst queue length:0
maximum backend burst queue length so far:0
aggregate number of times packets are requeued:0
aggregate number of times packets are dropped by PktAgingList:0
# of pkts dropped due to large inner (encap) hdrs:0
number of times packets are dropped by burst queue:0
number of packets delivered by burst queue:0
number of packets dropped by packet steering:0
number of packets dropped due to pkt length exceeds vNic mtu:0
}
The parts to note are:
running out of buffers:891
pkts receive error:0
1st ring size:512
2nd ring size:512
# of times the 1st ring is full:891
Ring buffer 2 is used for large packets, so unless you have jumbo frames configured on your network and servers, this may not be used.
The OS is not pulling data from the driver fast enough and the buffer is filling up and packets are being dropped. Can we do something about this - of course we can. This is where tuning your OS comes into it.
While a buffer size of 512 is fine for most workloads, you can change these values up to a maximum of 4096.
There's VMware KB Article but in Windows, open the driver advanced properties and change Ring Buffer #1 size to 4096, Ring Buffer #2 size to 4096, set Small RX buffers to 8192 and while you are there, set Receive side scaling to ON.
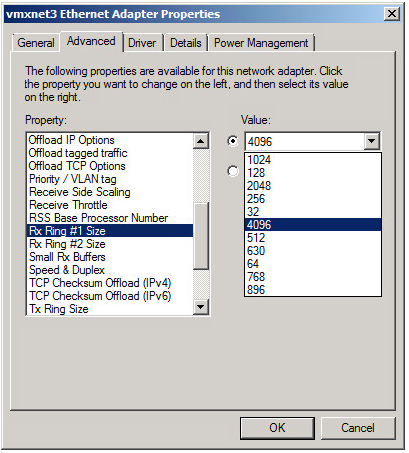
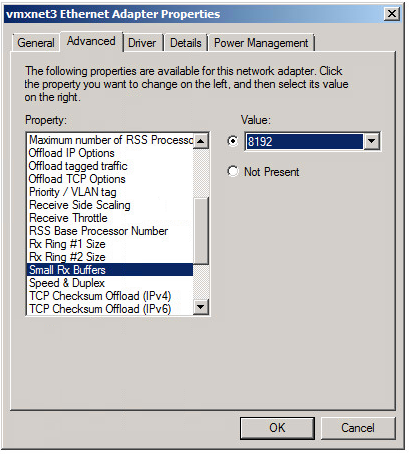
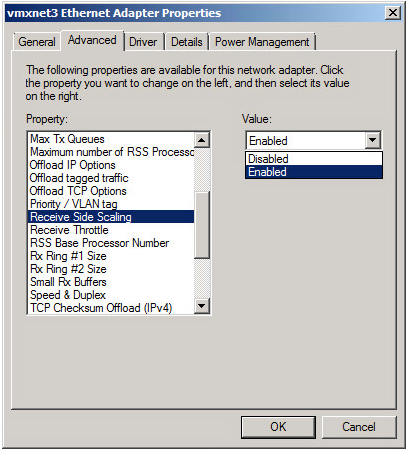
This will mean that the OS uses a bit more memory - but the buffers should be sufficiently large enough to allow the OS to catch up.
Where we have implemented these changes on servers we are no longer seeing RX packets dropped due to full buffers.
There's a great article which delves into a bit more detail than I have provided here: VMXNET3 RX Ring Buffer Exhaustion and Packet Loss – vswitchzero
As with any OS/driver tuning, then make sure you are making the change for the right reason and be aware that no change comes without potential side effects. In this case we had a busy server with a lot of small packet network traffic.
However in this case we have only seen positive reduction in retransmits. Wireshark packet analysis of remaining retransmits was all traces to internet targets - in which case that is TCP/IP doing it's thing correctly.
So next time you think you have a network issue - it may pay to check the OS...
Hello, would you like to hear a TCP joke?
Yes, I'd like to hear a TCP joke.
OK, I'll tell you a TCP joke.
OK, I'll hear a TCP joke.
Are you ready to hear a TCP joke?
Yes, I am ready to hear a TCP joke.
OK, I'm about to send the TCP joke. It will last 10 seconds, it has two characters, it does not have a setting, it ends with a punchline.
OK, I'm ready to hear the TCP joke that will last 10 seconds, has two characters, does not have a setting and will end with a punchline.
I'm sorry, your connection has timed out... ...Hello, would you like to hear a TCP joke?
you to hear Hello, UDP joke would