Getting started with the AWS S3 CLI
Although there are many fantastic tools that wrap a GUI around your s3 buckets nothing in my opinion beats becoming proficient with a command line. Let's take a look through some common commands you can use against our object storage platform (or pretty much any other object platform).
Installing the CLI
Visit the Amazon AWS CLI installer page and select your flavour/preferred method of installing (command line vs gui)
https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
Pro tip though, most likely if you are using some form of package manager like I am on my Macbook with brew installed, you can simply run something like the following, so just do a package search
brew install awscli
Configure a vBridge profile
We need to configure the CLI and add a profile with your vBridge access keys that are associated with your object tenancy.
First, open up MyCloudSpace and go into your tenancy and grab the keys via the Access keys button. This will reveal your access key and you can also add additional keys or remove them via this interface.
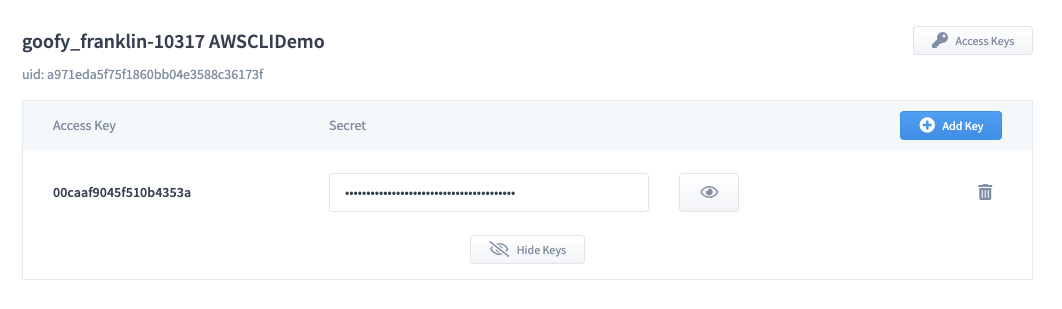
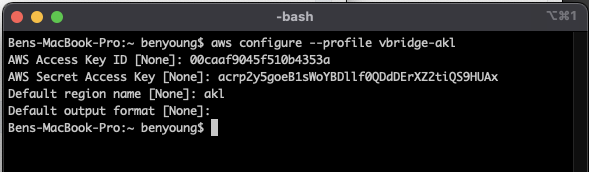
Now, lets jump to the command line and let's create a vbridge-akl profile for our Auckland region.
aws configure --profile vbridge-akl
Ok now some points to note, when issuing commands now you need to ensure you use this profile as well as the endpoint, listed in MyCloudSpace but;
- Auckland is https://s3-akl.mycloudspace.co.nz
- Christchurch is https://s3-chc.mycloudspace.co.nz
So a basic command would be a list or "ls" command, and we would then append the profile and endpoint to be
aws s3 ls --endpoint-url https://s3-akl.mycloudspace.co.nz --profile vbridge-akl
Creating a bucket
Pretty much the first thing you are going to need to do before you write any data is creating a bucket and thankfully it is pretty simple, to create a bucket called awsclidemo1 we would issue the "mb" or make bucket command;
aws s3 mb s3://awsclidemo1 --endpoint-url https://s3-akl.mycloudspace.co.nz --profile vbridge-akl

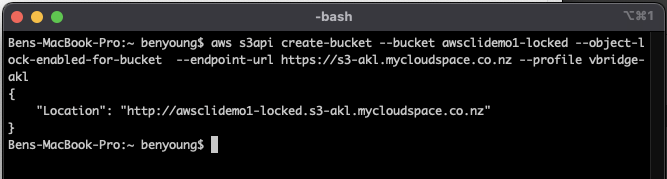
Now what if you want to create an object locked bucket? This allows you to use it for immutability with say Veeam Backup and Replication for scale out backup repositories, we need to issue s3api commands not s3 commands, slightly different but just as simple
You need to specify after create-bucket
- --bucket which is the name of the bucket
- --object-lock-enabled-for-bucket which tells the object platform to enable lock for the bucket
aws s3api create-bucket --bucket awsclidemo1-locked --object-lock-enabled-for-bucket --endpoint-url https://s3-akl.mycloudspace.co.nz --profile vbridge-akl
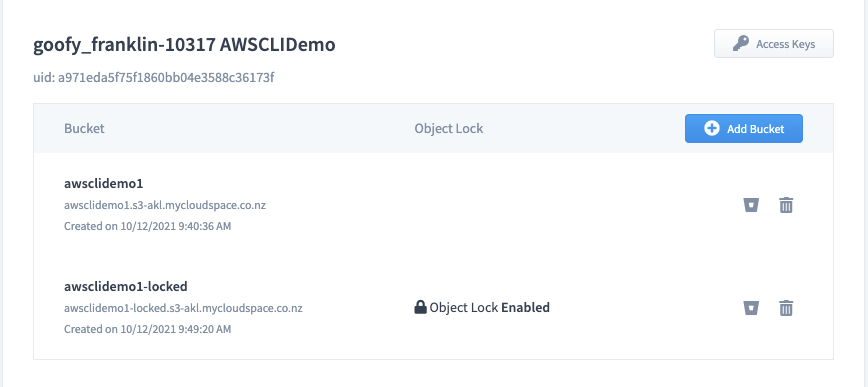
So now, if we "ls" we should see both of our buckets

This is mirrored in MyCloudSpace
Uploading files
Now we have a bucket, let's upload some files. I have a blood cell data set which i want to store up in the object platform so my application can pull these down on demand. Let's get them up there in our awsclidemo1 bucket.
We want to issue a "cp" or copy command and it is in the format of
aws s3 cp <source> <destination> (optional)--recursive
Here is the dataset on my local machine, located in ~/downloads/blood-cell-dataset
This contains a number of sub folders and I want all of these up so i need to also issue the --recursive command to make sure we get it all
My command then looks like this, to upload to the root of our awsclidemo1 bucket
aws s3 cp ~/Downloads/blood-cell-dataset/ s3://awsclidemo1/ --recursive --endpoint-url https://s3-akl.mycloudspace.co.nz --profile vbridge-akl
It will buzz away and fire them all across to the bucket
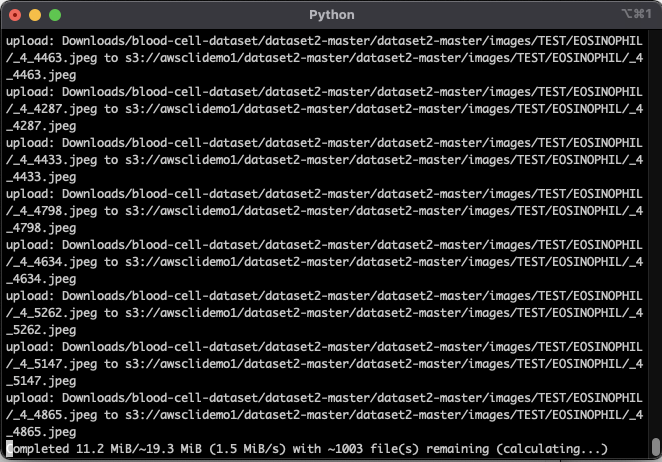
Now if I perform our ls command on the bucket the folder structure should be mirrored as below with the finder window and the output from the bucket

Easy as that.
If you want to copy from the bucket back to a local destination just start with s3://bucketname as the source and then your local path as the destination
Summarise bucket
Now we have uploaded, we better check that all the objects made it up right? the "ls" command has a few options and one of which is the --summarize command.
This can be used with or without --recursive. For our example I want a summary of all the objects and their size so we can reconcile against our local copy.
aws s3 ls s3://awsclidemo1 --summarize --recursive --endpoint-url https://s3-akl.mycloudspace.co.nz --profile vbridge-akl
This will then look through your bucket and spit out a summary
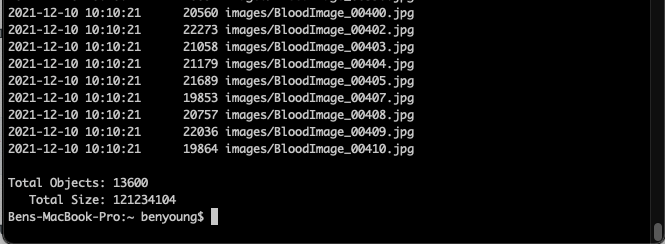
This aligns with my local copy so we can rest knowing all of our files made it.
Removing objects
Looking at my dataset, I realised i had an additional copy of a lot of the dataset image in the root folder called images, these are already in the dataset folder so let's remove that folder, note;
- we have now added /images after our s3 uri
- we have added the --recursive command
aws s3 rm s3://awsclidemo1/images --recursive --endpoint-url https://s3-akl.mycloudspace.co.nz --profile vbridge-akl
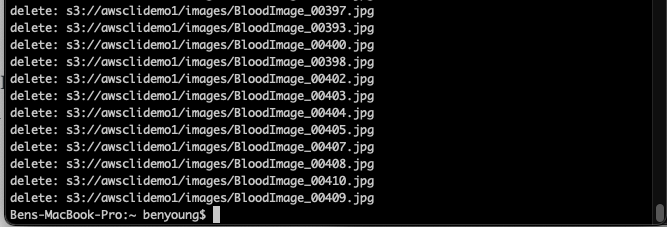
Now if we run our summarise or list commands we see the root object folder has been removed and we are left with just our dataset*-master folders

And the object count is smaller

Removing a bucket
Ok we have come full circle, let's clean up our buckets by removing them and all their contents. For this we use the "rb" or remove bucket command.
aws s3 rb s3://awsclidemo1 --force --endpoint-url https://s3-akl.mycloudspace.co.nz --profile vbridge-akl

Running an ls command will now show only our awsclidemo1-locked bucket, or you can see this is now no longer visible in MyCloudSpace
So if i run that same command and input the awsclidemo1-locked bucket name, this will remove this bucket.
If you have objects in an object-lock enabled bucket that have a policy on them you will not be able to remove the bucket or the objects until that policy has expired.
And it is now gone

If i run the ls command, it returns nothing so everything has now been cleaned up.
