So, we lost a disk 😱
Ok so not really all that scary, in fact something that historically happened often enough when you had hundreds of spinning disks in the Datacentre! I remember the joy of removing a storage array that filled almost an entire 42U rack (along with the associated noise and heat it generated) with a modern NVMe based array 3U in size and almost silent and a 1000% more performant (yes thats a real word)! 🤯 But I digress........
So, now we're in the glorious age of SSD/NVMe based storage 🙏🏼 and disk failures are far less common largely due to the fact we don't actually have any spinning disks anywhere! The disk failure in this instance was confined to a server, not just any server but a vSAN (virtual SAN) node.
vSAN is VMware's HCI (thats hyper-converged infrastructure) solution, where locally attached storage is pooled together to create a shared, distributed storage platform. Each node in the cluster contributes storage, compute, and networking resouce with vSphere as the virtualization hypervisor that glues it all together! We have four vSAN nodes in this cluster.

You'd think given its a modern hot plug SSD, just rip and repalce job done right .... well not quite !?😨 Physically replacing the SSD is easy, yep press the latch and pull out the disk all while the server carries on happily doing its thing (just make sure you pull the right disk here!). With the new disk in its time to see what the vSphere thinks of things.........

Ok, so thats not ideal! Time to jump onto the host cli and see what we can see......
vdq is your friend here, it's not a new utility .................. in fact William Lam wrote about it a number of years ago here. First of lets look at the status of our disk group(s): vdq - iH
[root@esx3:~] vdq -iH
Mappings:
DiskMapping[0]:
SSD: naa.5002538b00432120
MD: naa.55cd2e4155e42ea5
MD: 5218993f-6541-d85f-34a9-58d06bbe8a0c
First sign that some thing is wrong here is the string used in the disk mappings for device names, generally we'd expect these to be consistent, like "naa.xxxxx" - one of these things ain't like the other! Further to this we can see that we have three disks in our disk group (1 caching disk "SSD" and two capacity disks "MD") - yep, MD is misleading here as all our disks are SSD's. Historically, it was normal to have an SSD for the caching tier and Magnetic Disks for capacity........ 🤷🏼♂️
So lets dive in and get a little more detail on the individual disks, in particular keep an eye on the "state": vdq - iq
[root@esx3:~] vdq -iq
[
{
"Name" : "naa.55cd2e4155e42ea5",
"VSANUUID" : "",
"State" : "Eligible for use by VSAN",
"Reason" : "None",
"IsSSD" : "1",
"IsCapacityFlash": "0",
"IsPDL" : "0",
"Size(MB)" : "3662830",
"FormatType" : "512e",
"IsVsanDirectDisk" : "0"
},
{
"Name" : "naa.5002538b00432120",
"VSANUUID" : "5236b53c-32d6-545e-9d05-6a60314259b4",
"State" : "In-use for VSAN",
"Reason" : "None",
"IsSSD" : "1",
"IsCapacityFlash": "0",
"IsPDL" : "0",
"Size(MB)" : "763097",
"FormatType" : "512e",
"IsVsanDirectDisk" : "0"
},
{
"Name" : "naa.58ce38e91154f2ea",
"VSANUUID" : "5217e435-c57a-134c-f9f0-9ee3ac31a91c",
"State" : "In-use for VSAN",
"Reason" : "None",
"IsSSD" : "1",
"IsCapacityFlash": "1",
"IsPDL" : "0",
"Size(MB)" : "3662830",
"FormatType" : "512e",
"IsVsanDirectDisk" : "0"
},
{
"Name" : "",
"VSANUUID" : "5218993f-6541-d85f-34a9-58d06bbe8a0c",
"State" : "In-use for VSAN",
"Reason" : "None",
"IsSSD" : "0",
"IsCapacityFlash": "0",
"IsPDL" : "1",
"Size(MB)" : "0",
"FormatType" : "Unknown",
"IsVsanDirectDisk" : "0"
}
Right, so looks like we have three disks with a state of "In-use for VSAN" and one that is "Eligible for use by VSAN" - thats our new replacement. Additionally we can see some detail on the failed disk which which has now been physically removed but is still technically part of the group:
- Name: string is empty
- VSANUUID: matches string referenced in the disk group that was not "naa." format
- IsSSD: 0/false??! All our disks are SSD's
- IsCapacityFlash: 0/false (well it was capacity flash)
- IsPDL: 1/true - Permanent Device Loss, kinda speaks for itself here
- FormateType: Unknown - its been removed so thats probably expected
Our next step is to remove the failed disk from the group (its not coming back). For this we use an old friend, esxcli:
esxcli vsan storage remove -u 5218993f-6541-d85f-34a9-58d06bbe8a0c
Before we can add the replacement we actually have to let vSAN know its going to be used as Capacity Flash:
esxcli vsan storage tag add -d naa.55cd2e4155e42ea5 -t capacityFlash
And finally we just add it as a capacity disk to the existing disk group:
esxcli vsan storage add -s naa.5002538b00432120 -d naa.55cd2e4155e42ea5
So now when we re-check the disk group the world is a happy place once again 😁
[root@svakl1esx3:~] vdq -iH
Mappings:
DiskMapping[0]:
SSD: naa.5002538b00432120
MD: naa.55cd2e4155e42ea5
MD: naa.58ce38e91154f2ea
If you prefer the GUI to the CLI then we can do that too:
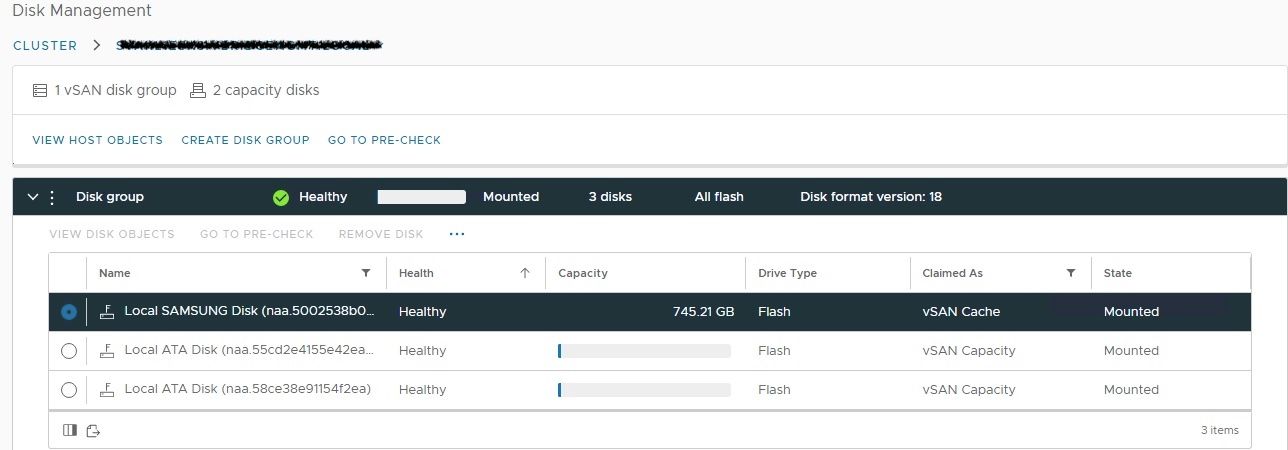
Nothing too dramatic really, but can be a little unnerving if you've not been through it before. And given the reliability of modern SSD's and NVMe based storage hopefully its not something you'll have to deal with that often. Job done, happy days 👋🏼