GPU, Tensorflow and Linux
Whilst AI has grabbed the headlines with tools like ChatGPT and Midjourney, there is more to it than that. Using your own data and local services, you can train your own models to gain insights from your own tailored data sets.
We announced our vGPU driven cluster here at the end of last year, and while most of the current use cases revolve around accelerated desktop and RDS for graphics capability, I am more interested in AI/ML type operations and how we can use the GPU profiles for that.
Some time ago we had an internal development project based on a workstation with multiple graphics cards, Linux and Docker. While it worked well, it wasn't quite ready for the prime time. So how do we fare on a 'proper' solution?
The new cluster uses Servers with A40 nvidia grid gpu. We have enterprise licensing and access to the nvidia tools and proprietary drivers. What do we need to do differently?
Firstly we deploy a VM on the new cluster with a default vGPU profile. Tensorflow is also currently built against CUDA11.2, not the latest 12. So we need to take care in the versions we run with. The first stage here is to select Ubuntu 20.04 rather than 22.04.
Boot from Ubuntu 20.04 iso and start following the normal setup. Hint: the nvidia cuda tools and dependencies are quite large, so boot disk needs to be a reasonable size (100GB).
Just run through the base installer. 20.04 doesn't magically detect the GPU at install time nor prompt to install 3rd party drivers.
After rebooting into new VM, first thing we do is install dkms.
sudo apt install -y dkms
This is the dynamic kernal module system. It will install a bundle of compile and build tools to allow the nvidia kernal driver to be built to match whatever the current kernel version you are running.v
Next step is that we mount the guest drivers on the VM via an ISO. We have an ISO loaded into MCS which contains the guest packages and our nvidia license token, so for obvious reasons I'm not posting that here. The guest drivers are available to anyone with access to the nvidia licensing portal.
root@prs-gpu01:~# mount /dev/cdrom /mnt
mount: /mnt: WARNING: source write-protected, mounted read-only.
root@prs-gpu01:~# ls /mnt/guest_drivers
52824_grid_win10_win11_ser.exe nvidia-linux-grid-525_5258.deb nvidia-linux-grid-525-5258.rpm nvidia-linux-x86_64-525850.run
root@prs-gpu01:~# ls /mnt/client_configuration_token.tok/mnt/client_configuration_token.tok
We need to install the driver, copy the token to /etc/nvidia/ClientConfigToken/ and edit gridd.conf to enable the appropriate feature
dpkg -i /mnt/guest_drivers/nvidia-linux-grid-525_5258.deb
cp /mnt/client_configuration_token.tok /etc/nvidia/ClientConfigToken/
sed -i 's/FeatureType=0/FeatureType=4/g' /etc/nvidia/gridd.conf
Which means we want to be a 'Virtual Compute Server' rather than unlicensed. At this point we either restart nvidia-gridd or reboot. And we will do a couple of basic checks to see that the vGPU is working and licensed.
sysadmin@prs-gpu01:~$ nvidia-smi -q | egrep '(Product|License)' Product Name : NVIDIA A40-8Q Product Brand : NVIDIA RTX Virtual Workstation Product Architecture : Ampere vGPU Software Licensed Product Product Name : NVIDIA RTX Virtual Workstation License Status : Licensed (Expiry: 2023-3-5 20:3:8 GMT)
Well, that's a great start, We have a linux VM with the correct nvidia grid drivers installed and we can see the A40 vGPU passed through from the underlying cluster.
From here on down, the setup is quite specific. You can see why devops and containers are the way to go in the long term when building an operational platform.
But now we need the tools to work. One gotcha is that if you try and install e.g libcuda11 from the Ubuntu repositories, it will uninstall the grid drives and install the open source drivers. These drivers do not support the datacenter grid GPU cards. Same if you install the nvidia cuda packages from the nvidia site. In fact, nvidia do post a handy warning. Buried deep in the Grid vGPU User Guide.

So we need to grab the runfile package and install that.
wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run
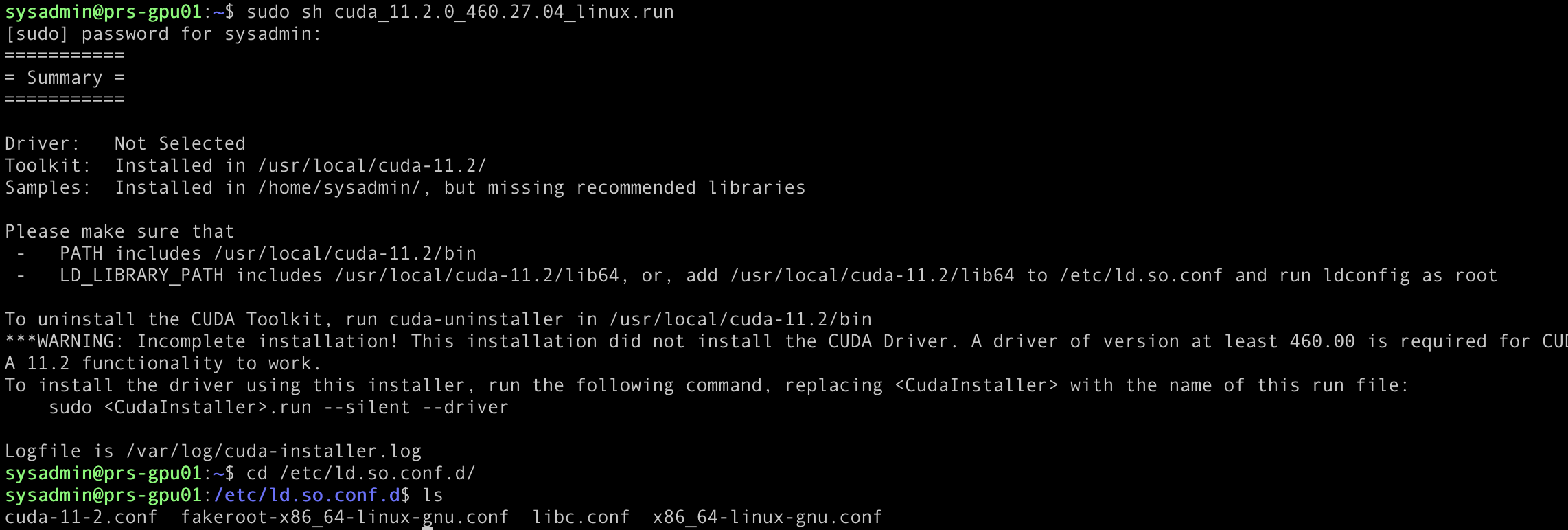
sudo sh cuda_11.2.0_460.27.04_linux.run
This gives you the option to skip the drivers.
Let that complete and note the output. the cuda-11-2.conf files appears to be in the right place.

Now we just need to give it a thrash. All the cool kids use Tensorflow and Keras right?
Lets install a few extra packages
sudo apt install graphviz libgl1-mesa-glx libhdf5-dev openmpi-bin python3-pip
And then install some pip packages (numpy, h5py, scipy tensorflow, keras) as local user.
The nvidia-tensorrt need a bit of hand holding and the nvidia-pyindex and we need to force back to 7.x version

My Keras training info comes from here. But that docker image is 5 years old. I just want to compare the new platform against our older dev platforms.


Training took ~11 seconds.
This is faster than the a high end graphics card, and this vGPU is on a par with the last generation (P4o 24GB/3840 cuda cores/Training 20s) when I last ran the test with access to the full hardware.
So the vGPU offering, while having less memory (8GB), it has 3 times the CUDA cores 10752 and training takes almost half the time. I'd call that a win.